Shivang Nagaria
Learning the Life!
Creating FileSystem from scratch
Reading Time: 4 MinI was reading a chapter on persistence from a book called OSTEP (a classic OS book by Prof. Remzi). It has all kinds of crazy things that I don’t hear about every day: storage devices, drivers, pages, virtualization of disk, and many other things.
The most interesting thing I found was the File System. The early stages were pretty basic - they didn’t even have a hierarchical structure (directories inside directories) - but things evolved pretty fast from there.
I was very intrigued, so I started building one from scratch. (Well, not exactly from scratch though, as it would have required an external HDD and a lot of low-level code).
How does the setup look?
There are 3 major pieces:
- Disk (which can be emulated)
- File System (The goldmine)
- Client (User, OS, other programs, etc)
I wanted to keep things simple and not trying to build fully-fledged File System. I restricted myself to these commands:
- touch
- mv
- cp
- rm
- mkdir
- ls
- pwd
I also planned to benchmark things wherever I could.
Iteration #1
As you know, disk operations are usually happen in blocks - you read or write one block at a time. The usual block size is 4KB, but I have kept it at 8 bytes here. The disk size I have chosen is 4KB (4096/8 = 512 blocks).
So, the name of the game is persistence. Your file system should work just fine after reboots and crashes. You need to have some structure in place that doesn’t change with restarts (unlike RAM, which loses its data as soon as the power is lost).
- first 10 bits = number of inodes in the system (i.e number of files, loosely)
- now comes the space for each inode (total = 51 bits)
- type -> 1 bit ( 0 for file, 1 for dir)
- starting block number -> 10 bit (don’t need offset as I’m fixing the size of each file to 2 blocks)
- name -> 2 bytes ( 16 bits )
- num_childs -> 3 bits (max allowed child = 7 )
- childs -> 7 * 3 = 21 bits
Sounds tricky to implement? Yes, it is. It is so tricky that I actually gave up on this and moved to simpler design.
Iteration #2
First of all, I fixed the block size of 1 byte (it makes life so much easier)
- 1st byte = number of inodes
- Space of each inode
- 1st byte - type (I know that it’s an overkill, well
**** ***!) - 2nd byte - name
- 3rd byte - data (I’m limiting the data to 1 byte, it’ll evolve from here. Don’t worry)
- 1st byte - type (I know that it’s an overkill, well
So, we have 4096 blocks and we can store 1365 files, each of 1 byte size.
In this attempt, I got following results (numbers are in microseconds):

Performance of rm is pretty bad here. There are multiple reasons
- We don’t have any in-memory structure to speed up file search. It is linear.
- For deletion, we are simply moving all the blocks by 3 bytes to the left. ( I know the tombstone method, that would be the next optimization)
Iteration #3
In this iteration, I have revamped the disk structure to keep filetype and filename together. Data blocks will now be filled from right to left, and inodes will be filled from left to right.
- 1st byte = number of inodes
- Space of each inode
- 1st byte - type (0 = Empty/tombstone, 1 = file, 2 = dir)
- 2nd byte - name
- At the end of the disk will be data blocks.
This is how it will look (similar to heap-stack kind of design)
-- START OF DISK--
#number_of_inodes block
#inode_#1 file_type
#inode_#1 file_name
#inode_#2 file_type
#inode_#2 file_name
.
.
.
#inode_#2 data
#inode_#1 data
-- END OF DISK--
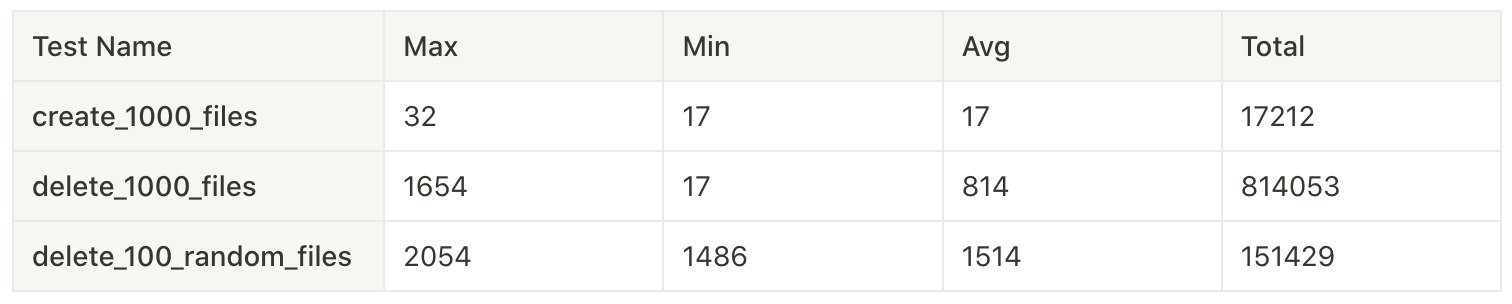
Here are the result of this iteration:

It looks like impl #2 is better than #3. It is simple and it has file_block_seek which keep tracks of blocks filled till now, thus making it more efficient.
Although, metrics for delete_1000_files test are pretty good given we have implemented the tombstone method.
Benchmark with file_block_seek improvement (you can see that creation is much faster now)
What’s next?
There are huge limitations with current approaches like
- File size is fixed (i.e 1 byte). Variable size is not supported
- File name is just 1 char
- Dir not supported
- Searching is linear
In the next phase, I’ll work on these and see where it takes me.